In data processing, log analysis, and system administration, identifying duplicate lines within a file is a common requirement. Duplicate entries can skew results, waste storage, or indicate potential issues. The Linux command line offers powerful tools to efficiently handle this task, primarily through a combination of the sort and uniq commands.
The sort | uniq Pipeline
The uniq command is designed to filter adjacent matching lines from an input file or stream. However, it’s crucial to note that uniq can only detect duplicate lines if they are directly next to each other . Therefore, to find all duplicate lines within a file, regardless of their position, the file must first be sorted. This is achieved by piping the output of the sort command into uniq.
The command structure sort $file | uniq --count --repeated is specifically tailored to identify and count these duplicate lines. Let’s break down its components:
sort $file: This command reads the specified$fileand outputs its contents with lines sorted alphabetically by default. This arrangement ensures that all identical lines are grouped together, satisfying the adjacency requirement foruniq. Thesortutility in Linux typically uses an external merge sort algorithm, allowing it to handle files larger than available memory by using temporary disk space . The primary limitation often becomes the available free disk space for these temporary files .|(Pipe): This operator redirects the standard output of thesortcommand (the sorted lines) to become the standard input for theuniqcommand.uniq: This command reads the sorted input.--count(or-c): This option modifiesuniq’s behavior to prefix each output line with the number of times it occurred consecutively in the input (which, after sorting, represents its total count in the original file) .--repeated(or-d): This option further filters the output to show only those lines that appeared more than once in the input .
When combined, uniq --count --repeated processes the sorted data, identifies lines that appear multiple times, and outputs only those duplicate lines, each prefixed by its frequency count .
Example Usage (Direct Command)
Consider a file named logfile.txt with the following content:
INFO: Process started
WARN: Low memory
INFO: Process started
ERROR: Connection failed
WARN: Low memory
INFO: Process startedTo find and count the duplicate lines directly, you would run:
sort logfile.txt | uniq --count --repeatedThe output would be:
3 INFO: Process started
2 WARN: Low memoryThis clearly shows that “INFO: Process started” appeared 3 times and “WARN: Low memory” appeared twice. The unique line “ERROR: Connection failed” is omitted because of the --repeated option.
Integrating with fzf for Interactive Selection
To avoid manually typing filenames, especially long or complex ones, you can use the command-line fuzzy finder fzf within a simple shell alias. This alias allows you to interactively select the file you want to analyze.
Creating the Alias:
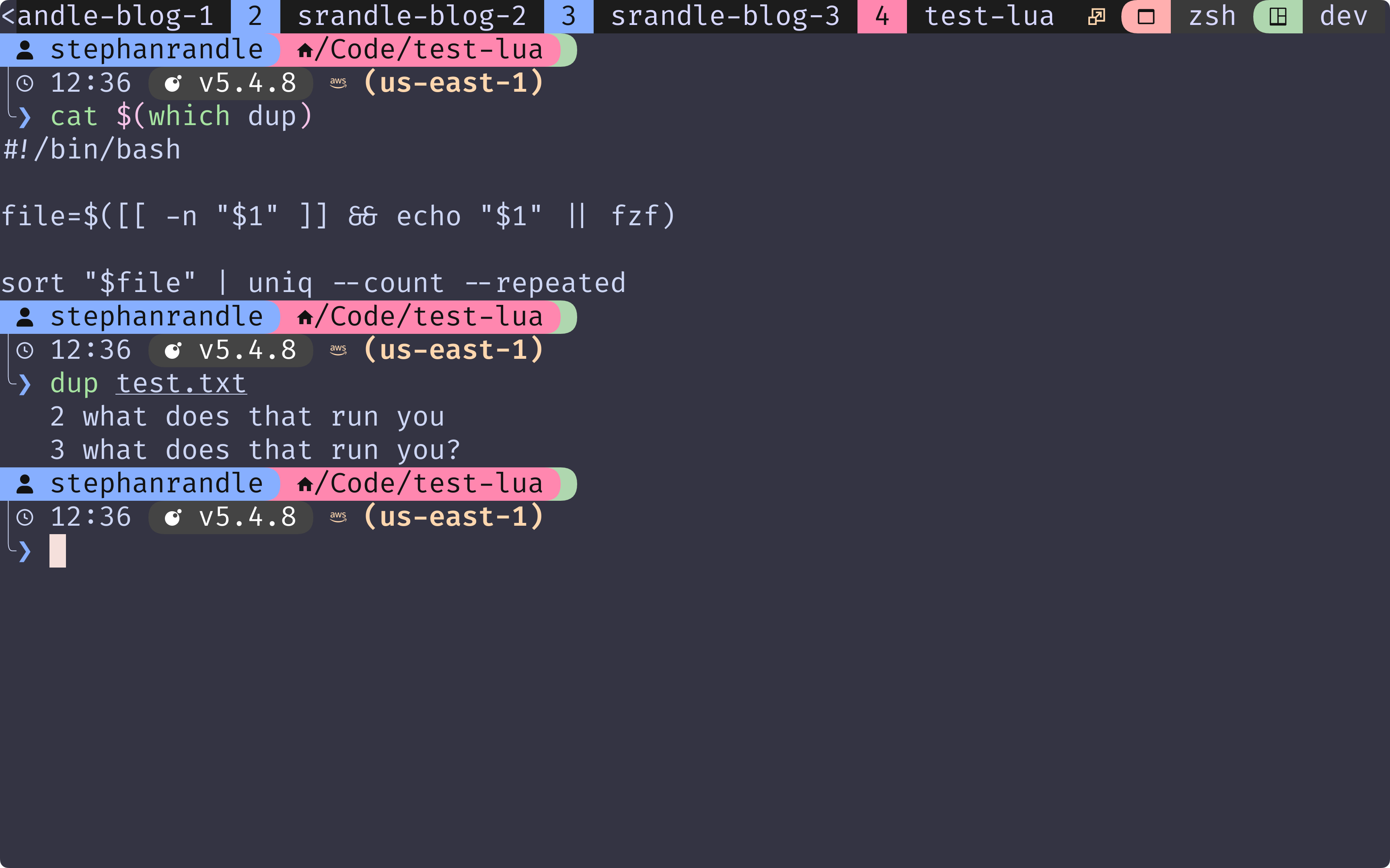
Inside of your .zshrc or .bashrc create an alias that runs fzf for the filename
alias dup='sort "$(fzf)" | uniq --count --repeated'- Save the file.
Usage:
Navigate to the directory containing the files you want to check (or a parent directory), and run the alias:
dupThis will launch the fzf interface. Type to filter the list, use arrow keys (or Ctrl-J/Ctrl-K) to navigate, and press Enter to select the desired file. The script will then process the selected file and display the duplicate lines and their counts.
Considerations and Alternatives
- Performance: For very large files, the
sortprocess can be resource-intensive. Performance can sometimes be improved, especially with ASCII data, by setting the locale to C (LC_ALL=C sort "$file" | ...) . GNUsortcan also compress temporary files, which may help with disk space and potentially speed up operations on systems with slower disks . - Case Sensitivity: By default,
sortanduniqcomparisons are case-sensitive. If you need to treat lines like “Error” and “error” as duplicates, use the--ignore-case(-i) option withuniq:sort "$file" | uniq -i --count --repeated. - Just Unique Lines: If the goal is simply to remove duplicates entirely and keep only one instance of each line,
sort -u "$file"is often more direct thansort "$file" | uniq. - Script Robustness: The provided script includes basic checks for cancellation and non-file selections. More complex scenarios (e.g., needing to search specific directories, handling
fzferrors differently) might require a more elaborate script or a shell function defined in your shell’s configuration file (.bashrc,.zshrc). - Statistics: While specific benchmarks depend heavily on file size, content, hardware, and system load, the
sort | uniqpipeline is generally considered efficient for most common text processing tasks on Unix-like systems. The underlying external merge sort algorithm used bysortis designed to handle large datasets effectively .
This command pipeline, optionally combined with an interactive selection script using fzf, provides a standard and effective method for identifying and quantifying duplicate lines directly within the Linux terminal environment.